
Like many other companies, at Uptodown we’re deeply engaged in figuring out how to unlock the potential of AI.
As part of this exploration, we experiment with new tools, try to identify what can actually enhance our work, and play around with the latest AI releases every week.
The most striking impact we’ve seen this year is the massive boost in productivity when it comes to development—almost unbelievable for those of us who’ve been programming for decades.
As an example, just a few weeks ago we put together a fully functional social network just for fun. And this past weekend, we decided to explore the frontier of LLMs: what better way to gauge how close we are to AGI than by comparing it to the mind of a 10-year-old kid from the ’80s playing Monkey Island or Maniac Mansion?
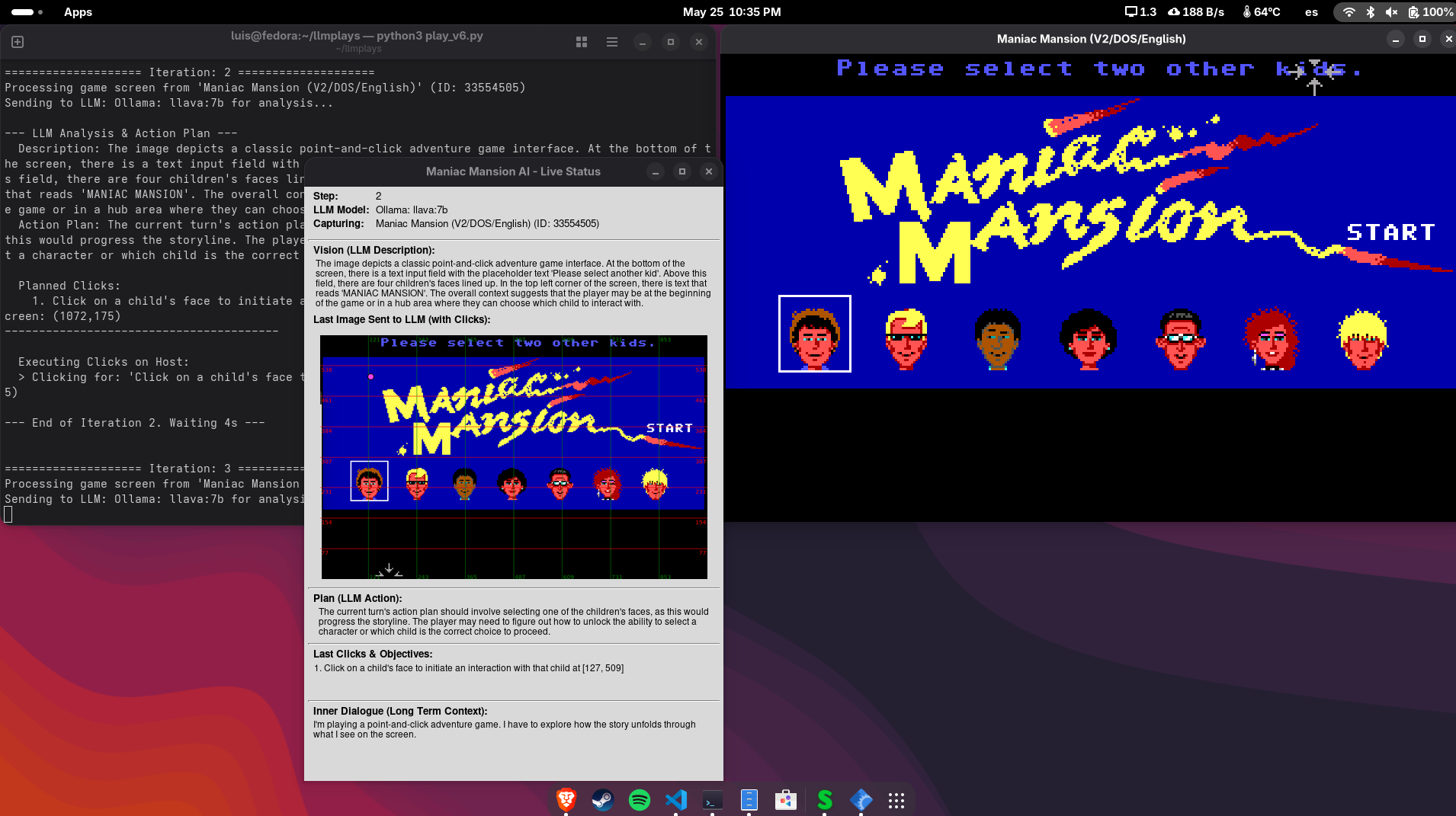
Inspired by LLMs playing Pokémon through emulators on Twitch, I set up a system that allows any vision-capable LLM (local and remote) to play classic MS-DOS graphic adventure games.
The workflow of this system is quite simple—though just a few months ago, building something like this would have taken weeks.
A Python script captures a specific area of a window running SCUMVM (where the game is being played), processes the image to prepare it for an LLM, manages the context, sends all the information to a vision-capable LLM, retrieves the suggested actions, executes them on the host system, and then repeats the cycle.
The basic components are:
- Fedora 42 with the X11 window server (to simplify screen capture)
- VSCode with Copilot (Gemini 2.5 Pro as pair programmer)
- Well make a single Python file containing the full script
- Ollama (using Llava:4b and Gemma3:4b, both of which support local vision), the ChatGPT and Anthropic API models as the «players»
VSCode—like any other AI-powered editor—is what really makes the difference here. It’s like having a junior developer who never gets tired: it refactors, debugs, writes code, and handles tedious tasks on command without a complaint.
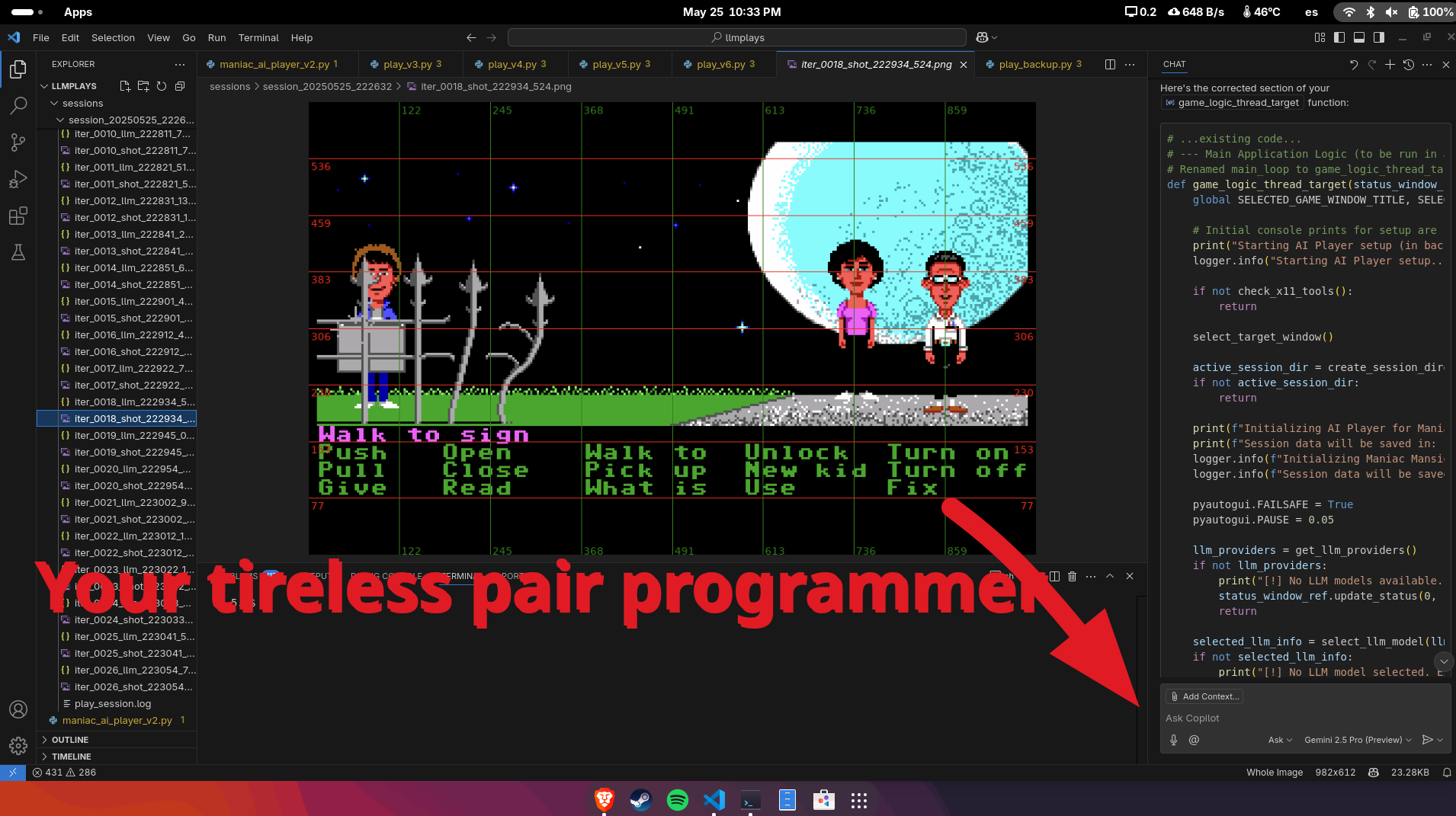
Your job is just to think through the more interesting challenges:
- Creating a grid overlay on the captured image to help the LLM precisely identify where to click
- Rewriting the internal dialogue on each iteration to help the LLM develop a long-term strategy
- Allowing model selection, integrating each local and remote LLM, dynamically choosing the capture window…
- Interpreting LLM commands and executing them properly on the host machine…
And with that setup, Copilot ends up doing the work of five junior developers in just a few hours. It’s almost absurd. You can see it in action here:
*All interactions with the game are performed by the LLM. Why does ChatGPT choose Bernard and Michael? ¯\_(ツ)_/¯
Google’s and Claude’s LLMs make the most progress in terms of advancing the game story, while local models still struggle with basic tasks like accurately determining where to click. But the solutions we’ve built go far beyond mere prototypes.
At current LLM service prices, completing Monkey Island or Maniac Mansion could end up costing hundreds or even thousands of dollars (once I iron out the final details, I might have one of them play live on Twitch for a few weeks). Maybe it’s time to build a dedicated home machine capable of running large models locally—something in the spirit of Andrés Torrubia’s setup.
Is all of this just an excuse to dust off old MS-DOS games and see how far LLMs can get with them? Of course. But programming has never been this much fun. AI has gone from being an incredible curiosity that you could chat with to something that’s having a tangible, almost absurd, impact on the real world—all in just a matter of months.
For a small team like Uptodown’s, this is a game-changer. With just 33 experienced people, we could potentially do the work of 100—if we manage to fit the pieces together.
Soon, we’ll begin to grasp what true abundance in software development really means—where weekend projects or one-person teams can achieve what once took entire teams for months.
Week 2 Update
I’ve replaced the overlaid coordinate grid with a numbered cell system. It has proven to be much easier for LLMs to understand and far more accurate than asking them to count pixels (based on https://github.com/quinny1187/GridGPT).
To help the LLM develop a long-term strategy, I’ve added a context memory that updates every ten iterations. At that point, the LLM pauses to generate:
- A map of all the rooms it has discovered based on the last ten screen descriptions, including how those rooms are connected.
- A concise and persistent list of objectives, based on everything it has read and inferred from interactions so far.
- The original context (as the first version had), summarizing its last ten actions to reduce repetition and improve variation in future actions.
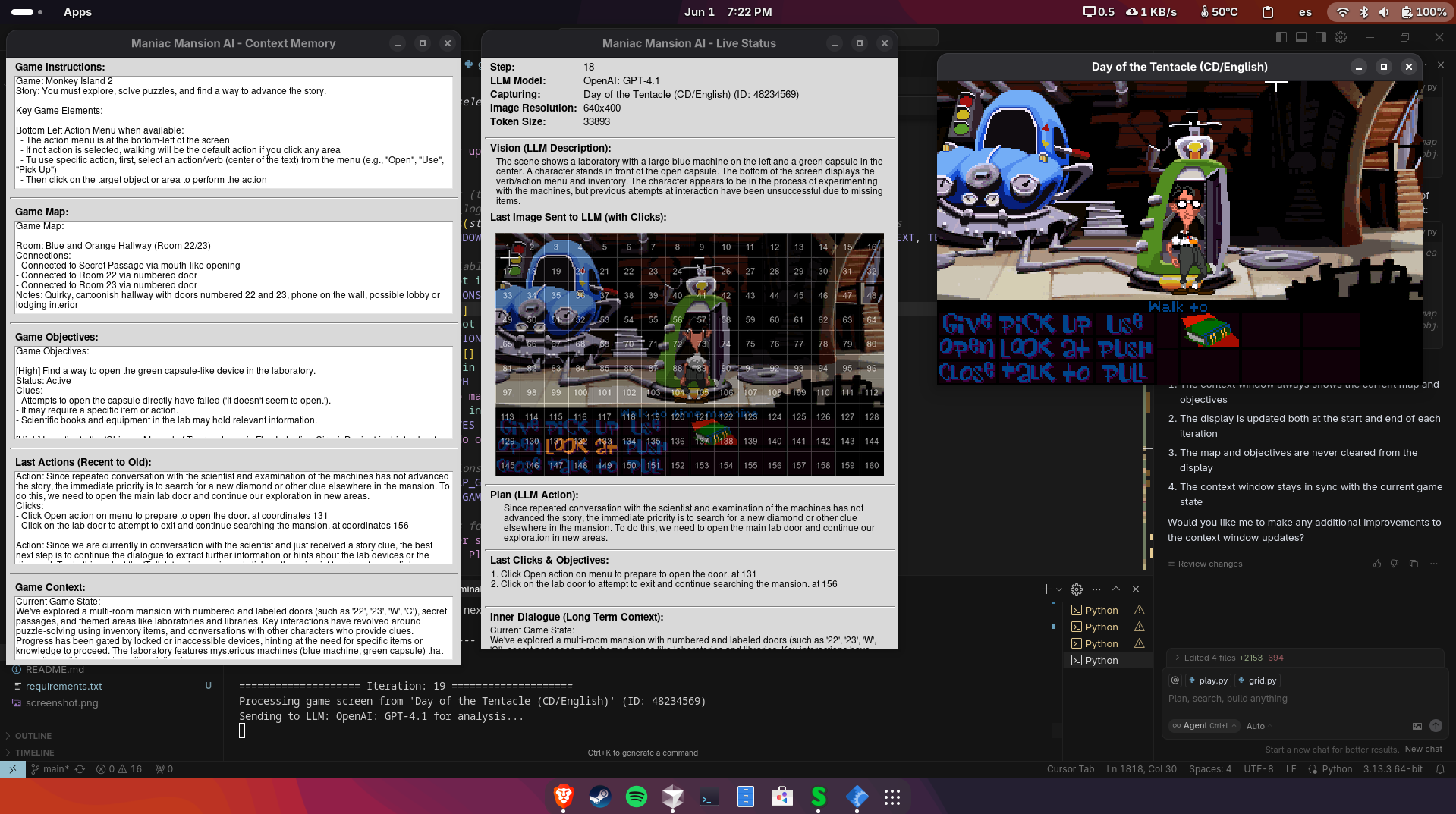
Finally, I’ve extended the game screen text duration to the maximum allowed, giving the LLM enough time to capture dialogue by taking a snapshot every three seconds.
With this setup and enough time (/ budget), we could build a solid benchmark to evaluate how well LLMs can play through this type of games. Day of the Tentacle, for example, has up to three separate timelines to solve puzzles!.
In just a few minutes, GPT-4.1 explored the main hall and the office, discovered the passage behind the clock leading down to Fred’s lab, and figured out that it needs a diamond to power the time machine. Granted, these LLMs have prior knowledge of popular games—just spotting the clock is enough to spark their curiosity :)
If I can find a way to cover the costs, I’ll set up a 24/7 Twitch stream to see just how far ChatGPT can go.
